When working with data, we often want to compare more than two groups.
- For example: Do students from different schools score the same on an exam?
- Do three marketing campaigns lead to the same average sales?
- Do four different diets result in the same average weight loss?
If you only had two groups, you could use a t-test. But what if you have three or more groups? Running multiple t-tests isn’t a good idea. This is where One-Way ANOVA comes in. “ANOVA” stands for Analysis of Variance, because the test works by comparing variation between groups to variation within groups.
What is One-Way ANOVA?
One-Way ANOVA is a statistical test used to compare the means of three or more independent groups to see if at least one group’s mean is significantly different from the others.
“One-Way” means there’s only one factor (independent variable) that defines the groups.
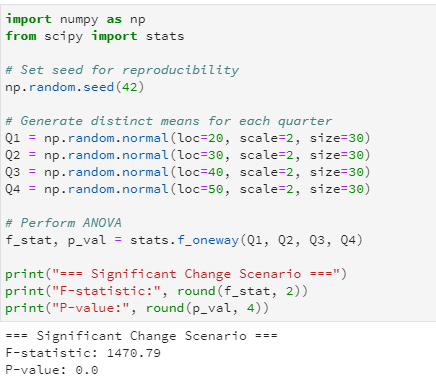
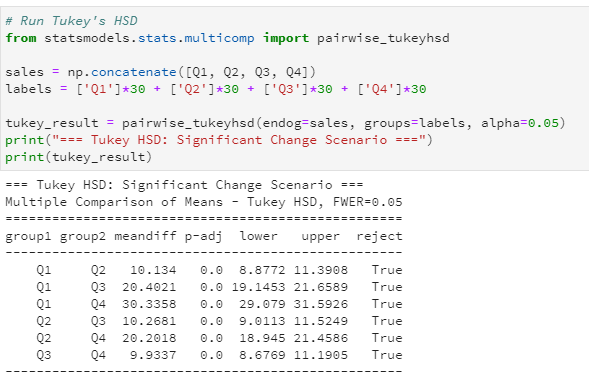
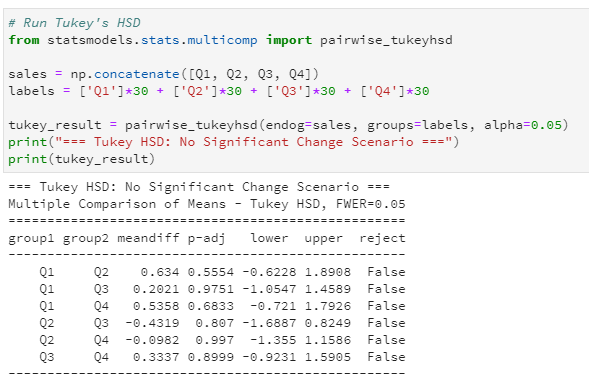
Example: "Quarter" when comparing quarterly sales.
How Does it Work?
Between-Group Variation → Measures how much the group means differ from the overall mean.
Within-Group Variation → Measures how much individual data points vary within each group.
If the differences between groups are large compared to the differences within groups, then at least one group mean is likely different.
Hypotheses in One-Way ANOVA
Null Hypothesis (H₀): All group means are equal.
Example: Average sales are the same in all four quarters.
Alternative Hypothesis (H₁): At least one group mean is different.
Example: At least one quarter’s sales are different from the others.