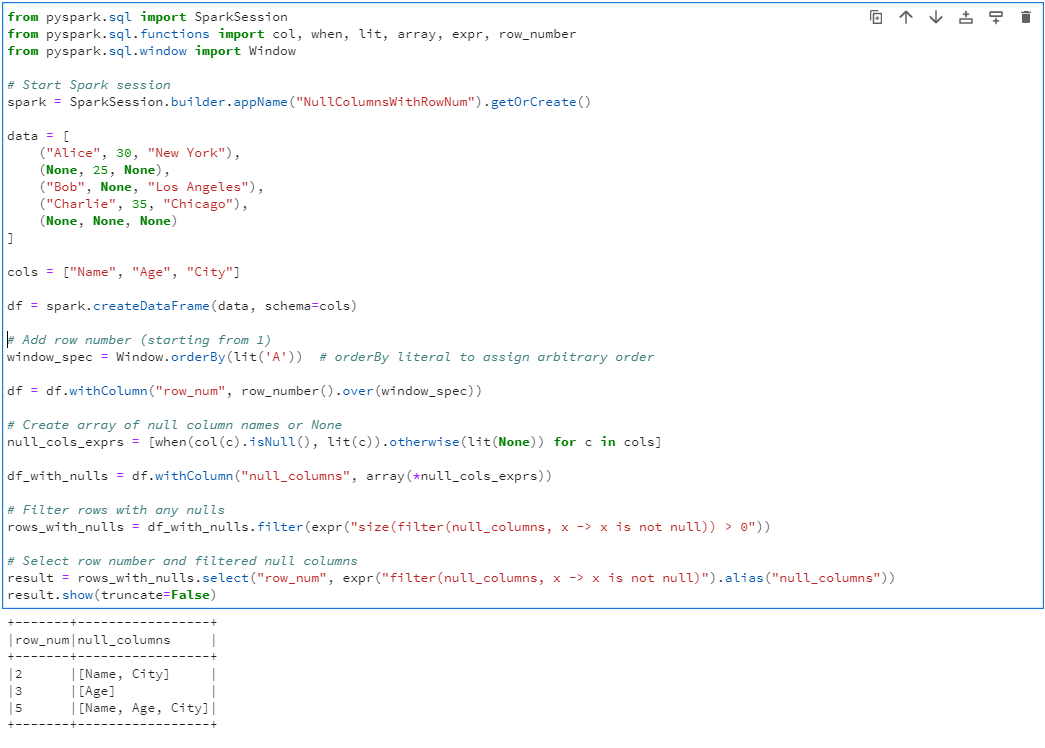
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, when, lit, array, expr, row_number
from pyspark.sql.window import Window
# Start Spark session
spark = SparkSession.builder.appName("NullColumnsWithRowNum").getOrCreate()
data = [
("Alice", 30, "New York"),
(None, 25, None),
("Bob", None, "Los Angeles"),
("Charlie", 35, "Chicago"),
(None, None, None)
]
cols = ["Name", "Age", "City"]
df = spark.createDataFrame(data, schema=cols)
# Add row number (starting from 1)
window_spec = Window.orderBy(lit('A')) # orderBy literal to assign arbitrary order
df = df.withColumn("row_num", row_number().over(window_spec))
# Create array of null column names or None
null_cols_exprs = [when(col(c).isNull(), lit(c)).otherwise(lit(None)) for c in cols]
df_with_nulls = df.withColumn("null_columns", array(*null_cols_exprs))
# Filter rows with any nulls
rows_with_nulls = df_with_nulls.filter(expr("size(filter(null_columns, x -> x is not null)) > 0"))
# Select row number and filtered null columns
result = rows_with_nulls.select("row_num", expr("filter(null_columns, x -> x is not null)").alias("null_columns"))
result.show(truncate=False)